HDFS
1. 概念与组成
HDFS以流式数据访问模式来存储超大文件。一次写入、多次读取。
组成:
- block:默认为64M。每个块分为多个分块(chunk),chunk作为独立的存储单元。
- namenode:Manager,管理文件系统的命名空间。记录每个文件中各个块所在的数据节点信息。
- datanode:Worker,存储并检索数据块,且定期向namenode发送他们所存储的块的列表。
- CLI:提供对HDFS的访问。
2. 文件读写图
Read:
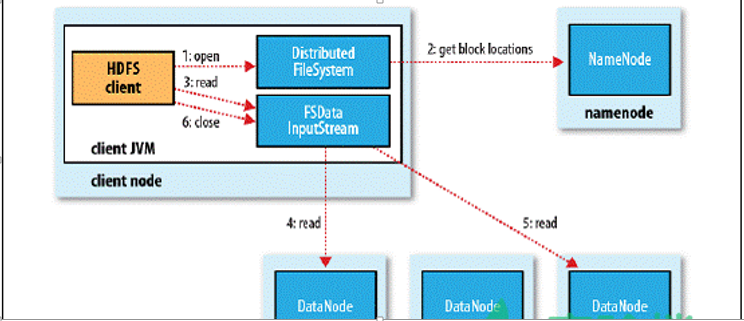 Read流程分析:
Read流程分析:
- 客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象是分布文件系统的一个实例;
- DistributedFileSystem通过使用RPC来调用NameNode以确定文件起始块的位置,同一Block按照重复数会返回多个位置,这些位置按照Hadoop集群拓扑结构排序,距离客户端近的排在前面;
- 前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流,客户端对这个输入流调用read()方法;
- 存储着文件起始块的DataNode地址的DFSInputStream随即连接距离最近的DataNode,通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端;
- 到达块的末端时,DFSInputStream会关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode,这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流;
- 一旦客户端完成读取,就对FSDataInputStream调用close()方法关闭文件读取。
Write:
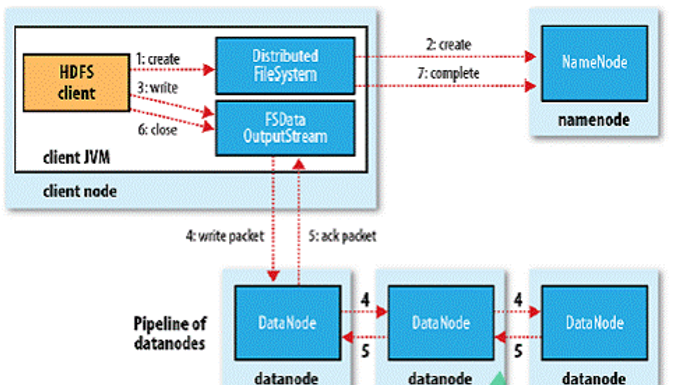 Write流程分析:
Write流程分析:
- 客户端通过调用DistributedFileSystem的create()方法创建新文件;
- DistributedFileSystem通过RPC调用NameNode去创建一个没有Blocks关联的新文件,创建前NameNode会做各种校验,比如文件是否存在、客户端有无权限去创建等。如果校验通过,NameNode会为创建新文件记录一条记录,否则就会抛出IO异常;
- 前两步结束后会返回FSDataOutputStream的对象,和读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream,DFSOutputStream可以协调NameNode和Datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小的数据包,并写入内部队列称为“数据队列”(Data Queue);
- DataStreamer会去处理接受Data Queue,它先问询NameNode这个新的Block最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的DataNode,把他们排成一个pipeline.DataStreamer把Packet按队列输出到管道的第一个Datanode中,第一个DataNode又把Packet输出到第二个DataNode中,以此类推;
- DFSOutputStream还有一个对列叫Ack Quene,也是有Packet组成,等待DataNode的收到响应,当Pipeline中的所有DataNode都表示已经收到的时候,这时Akc Quene才会把对应的Packet包移除掉;
- 客户端完成写数据后调用close()方法关闭写入流;
- DataStreamer把剩余的包都刷到Pipeline里然后等待Ack信息,收到最后一个Ack后,通知NameNode把文件标示为已完成
3. FileSystemAPI
使用FileSystemAPI来显示Hadoop中的文件:
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem. get(URI.create (uri), conf);
InputStream in = null;
try {
in = fs.open( new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
Usage:
hadoop FileSystemCat hdfs://localhost/user/tom/quangle.txt
4. CLI
hadoop fs -ls /
hadoop fs -lsr
hadoop fs -mkdir /user/hadoop
hadoop fs -put a.txt /user/hadoop/
hadoop fs -get /user/hadoop/a.txt /
hadoop fs -cp src dst
hadoop fs -mv src dst
hadoop fs -cat /user/hadoop/a.txt
hadoop fs -rm /user/hadoop/a.txt
hadoop fs -rmr /user/hadoop/a.txt
hadoop fs -text /user/hadoop/a.txt
hadoop fs -copyFromLocal localsrc dst #与hadoop fs -put功能类似。
hadoop fs -moveFromLocal localsrc dst #将本地文件上传到hdfs,同时删除本地文件。
管理员:
hadoop dfsadmin -report
hadoop dfsadmin -safemode enter | leave | get | wait
hadoop dfsadmin -setBalancerBandwidth 1000
5.java 接口
功能:
- 从Hadoop URL中读取数据
- 将本地的数据复制到Hadoop(写入)
- 新建目录
- 展示文件状态信息
- 列出文件
- 删除数据
IOUtils.closeStream()
IOUtils.copyBytes()
FileSytem.get
FileStatus
6. 序列化
序列化:将结构化对象转为字节流。
Hadoop使用Writable来封装数据。
具体类型的序列化:IntWritable、Text、ByteWritable、ObjectWritable、NullWritable、MD5Hash、ArraryWritable、MapWritable、SortedMapWritable。
序列化框架:WritableSerialization