Map-Reduce
1. Basic
Map阶段,Reduce阶段。每个阶段都以键值对作为输入和输出。
Input、Map、Shuffle、Reduce、Output。
术语
作业Job:客户端需要执行的一个工作单元。包括输入,MR程序,配置信息。 任务Task:Hadoop将Job分为若干个小任务来执行。主要分为map任务和reduce任务。 jobtracker:只有一个。调度tasktracker上运行的任务。 tasktracker:有多个。运行任务且将运行进度报告给jobtracker。 输入分片input split:将输入数据划分成等长的小数据块。Hadoop为每一个分片构建一个map任务。
2. Code
2.1 Mapper
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MinTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if(line.charAt(87) == '+') {
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if(airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
2.2 Reducer
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MinTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int minValue = Integer.MAX_VALUE;
for(IntWritable value : values) {
minValue = Math.min(minValue, value.get());
}
context.write(key, new IntWritable(minValue));
}
}
2.3 Main
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MinTemperature {
public static void main(String[] args) throws Exception {
if(args.length != 2) {
System.err.println("Usage: MinTemperature<input path> <output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MinTemperature.class);
job.setJobName("Min temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MinTemperatureMapper.class);
job.setReducerClass(MinTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3. MR 工作机制
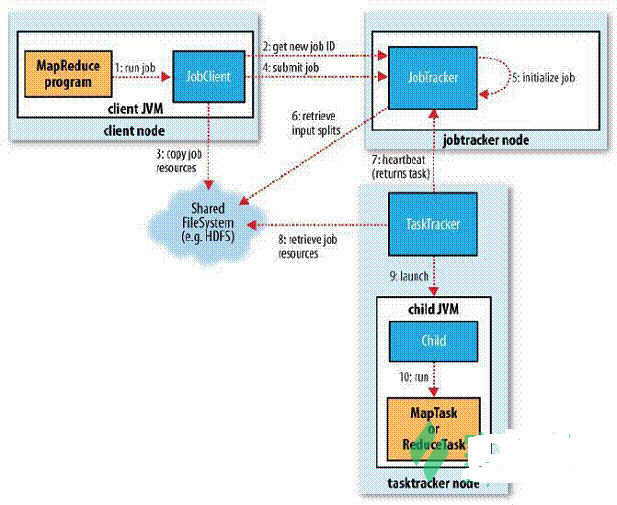
客户端:提交MapReduce作业。
jobtracker:协调作业的运行。
tasktracker:运行作业划分后的任务。
HDFS:共享作业文件。
- 作业提交,JobClient.runJob(conf)。本质是创建一个JobClient,执行submitJob方法。
- 向jobtracker请求一个新的作业ID(JobTracker的getNewJobId())
- 将运行作业所需要的资源文件复制到HDFS上(包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入分片信息),这些文件都存放在JobTracker专门为该作业创建的文件夹中,文件夹名为该作业的Job ID;
- 获得作业ID后,提交作业(调用JobTracker的submitJob())
- 作业初始化:JobTracker的作业调度器内对作业进行初始化。
- 从HDFS获取计算好的输入分片信息,然后为每一个分片创建一个map任务。运算移动,数据不移动
- TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户;
- 运行的TaskTracker从HDFS中获取运行所需要的资源,这些资源包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分等信息;
- TaskTracker获取资源后启动新的JVM虚拟机;
- 运行每一个任务;